
L’autre jour, j’ai téléchargé la version d’évaluation d’un logiciel appelé «DevonThink Pro». J’ai installé ce logiciel et je l’ai testé pendant une petite demi-heure. Et puis j’ai décidé de l’acheter. C’est assez rare pour mériter d’être signalé. Ce logiciel est extraordinaire et, une fois qu’on a commencé à l’utiliser, on se demande comment on a pu faire sans. DevonThink permet de stocker des informations de manière intelligente et hiérarchisée, puis de les exploiter en tissant des liens logiques entre elles. Le processus se déroule ainsi: l’utilisateur crée une base de données dans DevonThink et importe ses documents (ou indexe des documents sans les importer), il lui reste ensuite à créer une arborescence de dossiers et à classer ses documents dans cette arborescence pour mettre en oeuvre les puissantes fonctions de classement de ce logiciel.
L’insertion des documents dans la base de données est très facile. Elle peut être réalisée de plusieurs manières. D’abord, on peut glisser et déposer un fichier depuis le Finder vers la fenêtre de DevonThink ; le fichier sera alors automatiquement inséré soit à la racine de l’arborescence si on a lâché son icône n’importe où dans la fenêtre du logiciel, soit dans le répertoire spécifié si on a lâché le fichier sur ce répertoire. Ensuite, il est possible d’utiliser de nombreux AppleScript livrés avec le logiciel: on peut par exemple sélectionner un morceau de texte dans Safari ou dans Aperçu (ou toute autre application Cocoa) et utiliser l’AppleScript dédié pour insérer ce texte dans un nouveau fichier RTF créé par DevonThink. Finalement, on peut importer dans DevonThink des sites web, depuis n’importe quel navigateur et par l’intermédiaire de bookmarklets, soit sous forme de signets (le contenu n’est alors pas enregistré, puisqu’un signet n’est qu’une référence vers la page sur le Web) soit en réalisant une WebArchive de la page ciblée (le contenu est alors archivé dans DevonThink pour consultation hors-ligne). L’importation est dans tous les cas très facile, et d’autant plus depuis la version 2.0 du logiciel dans laquelle un panneau latéral, comme dans Yojimbo ou SOHO (ex-StickyBrain), permet d’importer des documents sans lancer DevonThink. Un détail à signaler, puisque le diable est dans le détail: on peut afficher le contenu d’un document dans DevonThink (voir plus bas), sélectionner une phrase et choisir en deux clics de définir cette phrase comme titre du document. C’est particulièrement pratique lorsqu’on importe des pages sur internet qui ont un titre générique (par exemple, toutes les pages du site ont pour titre le nom du site, quel que soit leur contenu) ou des documents qui ont un titre codé («cc_ed-orig_1804.pdf» est moins parlant que «Code Civil - Edition Originale de 1804»).
DevonThink «mange» de nombreux types de documents: pages web, documents en texte plain, fichiers Word, RFT, ou plus généralement de traitement de texte, PDF, Excel ou plus généralement de tableur, de nombreux formats d’images, les signets (par exemple depuis un fichier exporté de Firefox), des flux RSS, des contacts, des e-mails, etc. A ce titre, on distinguera les formats qu’il peut lire et ceux qu’il peut écrire. Depuis la version 2.0, DevonThink peut lire les mêmes formats que QuickLook, c’est-à-dire tous les formats courants. Le logiciel peut aussi importer le contenu entier d’un répertoire qu’on glissera depuis le Finder vers sa fenêtre principale. Si un format de fichier n’est pas reconnu (ce qui est devenu très rare), une fenêtre «journal» le signalera, mais le fichier sera tout de même importé dans la base de données. Il est également possible d’indexer des fichiers sans les importer dans la base de données (ce qui économise de l’espace disque en évitant d’avoir ces fichiers en double). DevonThink insère alors dans la base de données une référence vers ces fichiers et, lorsqu’on supprime cette référence, il demande si l’on veut ou non effacer l’original du disque dur. Un peu comme iTunes en définitive, sauf qu’iTunes ne demande cela que lorsqu’on tente de supprimer une fichier depuis la Bibliothèque générale, alors que DevonThink offre ce choix à l’utilisateur quelle que soit la place du document dans la hiérarchie des dossiers créés.
L’interface de DevonThink peut être modifiée à souhait par l’utilisateur qui pourra notamment choisir entre six vues différentes (voir les captures d’écran ci-dessous): liste (comme dans l’explorateur de Windows 95: dossiers et documents affichés en même temps, possibilité de plier ou déplier grâce à une petite flèche à gauche de chaque dossier), icônes (simplement des icônes, cliquer dessus ouvre le dossier ou le document dans une autre fenêtre), colonnes (comme dans le Finder, un niveau de l’arborescence est représenté dans une colonne à gauche, un sous-niveau dans la colonne immédiatement à droite), séparation verticale (en haut les dossiers et les fichiers, comme dans la vue en mode liste et, en bas, une zone de prévisualisation du contenu du document sélectionné), séparation horizontale (la liste des dossiers et fichiers à gauche, la prévisualisation à droite), arborescence (version pro uniquement: la liste des dossiers à droite, la liste des documents en haut, la prévisualisation en bas). Depuis la version 2.0, DevonThink permet d’utiliser une vue CoverFLow (comme iTunes ou le Finder) et d’afficher les documents avec QuickLook. La meilleure vue est certainement celle en mode arborescence (et ce n’est pas pour rien qu’elle n’est accessible que dans la version Pro de DevonThink): la liste des documents présente, au choix, certaines propriétés: nom, date de création, date de modification, étiquette, taille sur le disque, nombre de mots, chemin, etc. Bien entendu, il est possible de classer les documents de haut en bas ou de bas en haut selon n’importe lequel de ces critères (on utilisera le plus souvent un classement descendant par date, du document le plus récent au plus ancien).
|
Fig. 1: les différentes vues proposées par DevonThink. Cliquez sur une vignette pour agrandir.
|
|||||
| Liste | Icônes | Colonnes | Séparation verticale |
Séparation Horizontale |
Arborescence |
Si DevonThink permet d’ajouter des fichiers existants dans la base de données, il permet aussi d’en créer de nouveaux. C’est donc à la fois un logiciel de traitement et de création. On peut ainsi créer des fichier en texte brut (Plain Text) ou en texte enrichi (Rich Text), des tableaux (simples, rien à voir avec Excel), des listes à cocher («outlining»). On remarquera l’existence d’un mode d’édition plein écran, ce qui est particulièrement agréable lorsqu’on désire ne pas être distrait par l’interface du système d’exploitation ou simplement lorsqu’on désire choisir les couleurs de fond et de la police de manière à ne pas se fatiguer les yeux.
Une fois les fichiers ajoutés ou créés, il reste à créer une arborescence logique. C’est certainement l’étape la plus difficile, car le logiciel laisse à l’utilisateur toute latitude dans ses choix. Un mauvais choix d’arborescence ne permettra pas d’exploiter DevonThink au maximum de ses capacités, alors qu’un bon choix permettra de gagner beaucoup de temps dans l’utilisation future des documents insérés dans la base de données. Pour créer une bonne arborescence, il faut partir du général pour aller au particulier. On prend une idée globale et on crée un premier dossier. Puis, on distingue dans cette idée plusieurs aspects qui seront autant de sous-dossiers. Chacun de ces sous-dossiers représentera un nouveau thème, qui pourra à son tour se présenter sous plusieurs facettes qui formeront autant de sous-dossiers. Il est normal qu’à la première utilisation on ne crée que quelques dossiers. Mais avec l’insertion de nouveaux documents dans la base de données, on ressent vite le besoin de rendre le classement plus précis et de créer de nouveaux sous-dossiers. Par exemple, si l’on prend la thématique «Nature», on pourra d’abord penser à créer deux sous-dossiers: «faune» et «flore». Quand on aura inséré plusieurs documents dans le dossier «faune», on ressentira certainement le besoin de créer de nouveaux sous-dossiers «mammifères», «oiseaux», «poissons», etc. Ensuite, parmi les mammifères, il faudra certainement distinguer les humains des animaux. Et ainsi de suite, la classification devenant de plus en plus précise.
Jusque là, DevonThink ne présente pas d’avancée formidable par rapport à ce que l’on connaît actuellement sous la forme de l’arborescence de nos systèmes de fichiers, organisés en dossiers et sous-dossiers. Si DevonThink ne permettait que de réaliser un tel classement, manuellement, il ne présenterait pas grand intérêt en dehors de celui de centraliser tous les documents dans une unique base de données qui peut faire l’objet de sauvegardes rapides et faciles. La «révolution» DevonThink survient quand on a déjà une arborescence précise et détaillée, avec peu de fichiers dans chaque dossiers (logiquement, plus on a de dossiers, moins il y a de fichiers par dossier). DevonThink analyse le contenu des documents de la base de données avec un puissant algorithme basé sur le nombre d’occurrences des mots employés dans ces documents. L’analyse est bien sûr opérée dès l’insertion d’un nouveau document dans la base de données, de manière totalement transparente pour l’utilisateur. Ainsi, après avoir inséré un nouveau document, on pourra demander au logiciel de suggérer un classement pour ce document. Si l’on insère par exemple un texte parlant de sociologie, le logiciel détectera qu’il s’agit d’êtres humains et suggérera automatiquement le dossier «humains» qui se trouve dans le dossier «mammifères» du dossier «faune». Le premier point intéressant est donc que DevonThink permet de classer rapidement et efficacement de long documents sans qu’il soit nécessaire de les lire pour déterminer leur contenu exact. Le classement est soit complètement automatique, avec un taux d’erreur qui est directement fonction de la qualité du classement originel créé par l’utilisateur (comprendre: si les dossiers sont bien organisés, et les documents existants déjà bien classés dans ces dossiers, le logiciel ne se trompera pas), soit de manière «assistée». Cette dernière manière fait intervenir l’utilisateur en lui suggérant plusieurs dossiers susceptibles d’accueillir le document inséré dans la base de données, ces dossiers étant présentés du plus pertinent au moins pertinent. Ce sera ensuite à l’utilisateur de faire son choix.
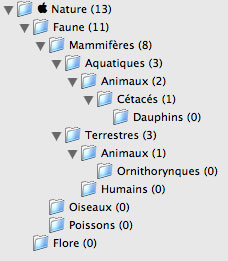
La première force de DevonThink est donc de permettre un classement rapide et efficace d’une importante masse de documents. La seconde force de DevonThink, qui est basée sur la même analyse logique du contenu des documents que la première, réside dans ses capacités à effectuer des rapprochements entre les documents. Le logiciel peut ainsi suggérer à l’utilisateur qui consulte un document de consulter un second document qui se trouve dans un tout autre dossier mais qu’il estimé lié d’une manière ou d’une autre au premier. Pour reprendre toujours le même exemple, on partira de la classification suivante: parmi les «mammifères», il existe deux grandes catégories: «terrestres», «aquatiques». Parmi les mammifères terrestres, certains pondent des oeufs (les protothériens, comme l’ornithorynque), d’autres non (comme l’être humain et le dauphin). On pourrait imaginer que l’utilisateur consulte un document PDF sur l’accouchement humain. Le logiciel suggérera d’abord à l’utilisateur de lire un premier article relatif aux dauphins et ensuite un second sur la naissance des bébés ornithorynques. Le premier intérêt de ces suggestions est évident: si l’utilisateur avait oublié l’existence du document sur les dauphins, le logiciel lui rappelle son existence. Le second intérêt est plus difficile à cerner, mais il est bien plus important. Dans une arborescence classique comme celle du Finder ou de l’explorateur Windows, quand on rentre dans un sous-dossier on perd généralement de vue le contenu du dossier parent ; autrement dit, lorsqu’on est au 12ème niveau de la hiérarchie, on ne se souvient plus de ce que contenait le 3ème niveau. Il est ainsi nécessaire d’opérer un choix à chaque changement de niveau. L’utilisateur partira en général de la catégorie la plus haute dans la hiérarchie (dans l’exemple, «mammifères marins»), qui est générale, pour descendre dans l’arborescence vers une catégorie plus spécialisée. De cette manière, l’utilisateur trouvera le document sur les ornithorynques s’il l’a classé parmi les mammifères terrestres (ce sont en réalité des mammifères semi-aquatiques, mais ils sont si différents des cétacés que ce choix se comprend), mais pas celui sur les dauphins car ceux-ci sont des mammifères marins. Or, on l’a vu, l’ornithorynque pond des oeufs contrairement au dauphin. L’article sur l’accouchement du dauphin est donc plus pertinent que celui sur l’ornithorynque bien qu’il soit plus éloigné dans l’arborescence. En réalité, DevonThink permet ici de résoudre les problèmes qui se posent lorsque plusieurs classifications sont possibles (en l’occurrence mammifères aquatiques/terrestres et protothériens/autres).
Ce qui fait l’originalité et la force de DevonThink, ce qui le place bien au dessus de tous ses concurrents, c’est sa capacité à prendre en compte simultanément une organisation verticale et une organisation horizontale des données.
On retrouve de genre de raisonnements dans les logiciels de tri basés sur les «tags» (par exemple, Yojimbo de BareBones). Les «tags» sont des étiquettes que l’on colle sur un document pour l’associer à un ou à plusieurs thèmes donnés. Les tags permettent ainsi d’établir une hiérarchie fixe, mais de retrouver les mêmes documents en effectuant des recherches transversales sur des thèmes différents. Cette méthode de marquage n’a cependant pas été retenue dans DevonThink, jusqu’à la version 2.0 du logiciel. Cela peut choquer pour un logiciel si puissant, mais c’est en réalité totalement justifié. En effet, lorsqu’on a de nombreux documents on peut rencontrer deux problèmes avec les «tags»: d’une part on ne sait plus quel(s) tag(s) assigner à un nouveau document, d’autre part on prend le risque de ne pas se souvenir qu’un tag existe déjà et de le créer à nouveau sous une autre forme. Par exemple, lors de l’insertion dans la base de données du texte de la Convention de La Haye sur la loi applicable à la responsabilité du fait des produits défectueux, on peut choisir les tags «droit international privé», «conflit de lois», «produits défectueux», ou «Convention de La Haye». Si l’on efface ce document et que l’on choisit quelques jours plus tard de finalement le réinsérer dans la base de données, on ne se souviendra pas forcément des tags assignés lors du premier ajout, et l’on risque fortement d’en oublier un ou plusieurs. Il est très difficile de choisir les tags corrects et de ne pas en oublier un en cours de route. Si c’est le tag «Convention de La Haye» qui est omis, une recherche sur ce tag ne renverra pas la Convention de La Haye sur la loi application à la responsabilité du fait des produits défectueux, ce qui est incohérent puisqu’il s’agit justement d’une Convention de La Haye ! Dans l’exemple précédent, on aurait également pu choisir «DIP» à la place de «droit international privé», «loi applicable» à la place de «conflits de loi», «vice caché» à la place de «produits défectueux» ou encore «CLH» à la place de «Convention de La Haye», au risque de créer un nouveau mot clé au sens identique à un mot clé déjà existant, mais différent dans la forme. Ainsi, une recherche basée sur le tag «droit international privé» donnera des résultants différents d’une recherche basée sur le tag «DIP», alors que le second n’est que l’abréviation du premier ! Ces risques sont d’autant plus élevés que le nombre tags a tendance à se multiplier de manière exponentielle. La version 2.0 de DevonThink adjoute automatiquement certains tags aux documents, en fonction de leur classement dans la hiérarchie. Chaque dossier est un «tag», comme dans le Gmail de Google mais, à la différence de ce dernier, il demeure possible de d’imbriquer les «tags» dans une hiérarchie. Bien entendu, DevonThink gère les tags insérée dans le Finder.
DevonThink permet également de créer des «répliques» des documents. Les répliques ne sont pas de simples copies. Ce ne sont pas non plus des références vers un unique document original. Le problème des copies est que si l’on modifie le premier exemplaire, la modification n’est pas reportée sur le second. Le problème des références ou alias est que le document original est toujours unique, il doit donc être placé dans un dossier déterminée et un choix est à opérer: on retombe ainsi sur le même problème. Les répliques sont des copies d’un même document liées entre elles. Ainsi, lorsqu’une des répliques est modifiée, toutes les autres le sont de la même manière. DevonThink gère cela très bien: il indique qu’un document a été répliqué en colorant son nom en rouge. Cependant, le système de réplication des documents ne signifie pas qu’il est impossible de créer des copies indépendantes les une des autres. C’est tout à fait possible, et le nom des documents en plusieurs exemplaires sera alors coloré en bleu. Il en résulte que si l’utilisateur voit le nom du document qu’il vient d’insérer se colorer en bleu, c’est que ce document se trouve déjà dans la base de données. Cela permet d’éviter les doublons de manière très efficace.
 |
| Fig. 2: Les fichiers dont le nom est en rouge sont des répliques d'un même fichier, les fichiers dont le nom est en bleu sont des copies, des doublons. |
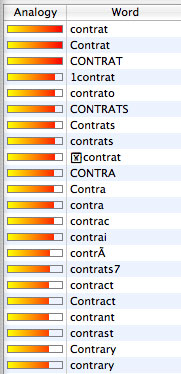
DevonThink permet également d’effectuer des recherches complexes dans la base de données. Il est ainsi permis de chercher dans le titre des documents ou dans leur contenu, dans l’adresse (URL) ou dans les meta-données associées au document. L’utilisateur pourra élaborer des requêtes complexes en choisissant de rechercher tous les mots (opérateur ET), n’importe quel mot (opérateur OU), la phrase entière (ces mots là, les uns à côté des autres dans cet ordre), ou des parties d’un ou de plusieurs mots (avec les jokers ? pour une lettre ou * pour un nombre indéterminé de lettres). La comparaison pourra être exacte, en tenant compte de la casse ou sans en tenir compte (parfois, c’est important: une histoire ce n’est pas l’Histoire !) ou approximative. Mais DevonThink va plus loin: il prend en compte les fautes de frappe et les fautes d’orthographe. Ainsi, si l’utilisateur recherche «mamifère», le logiciel lui suggérera automatiquement «mammifère». Ces suggestions sont également très utile lorsqu’un mot peut se présenter sous différentes formes, par exemple au féminin ou au masculin, au singulier ou au pluriel, à l’infinitif ou conjugué, voire décliné en différentes formes dans les langues à déclinaisons. DevonThink s’affranchit ici encore du problème des tags qui peuvent être orthographiés de différentes manières. Mais le système DevonThink n’est pas non plus sans faille. Il est ainsi plus pratique d’utiliser les tags dans un cas: lorsque les documents sont rédigés dans des langues différentes. Le système de mise en relation des documents entre eux étant basé sur une analyse textuelle, un document parlant de «vested rights» ne sera pas forcément mis en relation avec un document employant la traduction française de cette expression de droit anglo-américain, «droits acquis». En revanche, les critères de recherches «flous» autorisent une certaine marge d’erreur et permettent de trouver les documents partant de «contract» ou de «contrato» lorsqu’on chercher «contrat» (v. ci-dessous Fig. n°3).
DevonThink permet également de restreindre la recherche aux documents affectés par un certain état. Le logiciel permet par exemple de «verrouiller» des documents pour prévenir toute modification accidentelle, et l’on pourra spécifier que l’on veut rechercher parmi les documents verrouillés ou, au contraire, parmi les documents déverrouillés. De même, DevonThink permet d’assigner une couleur à un document. Un état pourra être associé à chaque couleur (au nombre de 7). On pourra ainsi colorier l’icône d’un document en jaune quand on l’insère dans la base de données, en bleu pendant qu’on est en train de le lire, en rouge quand on a terminé de le lire, en violet quand on l’a analysé, en vert quand on l’a cité dans un écrit, en gris lorsqu’on est pas certain de son authenticité, etc. Finalement, il est possible de restreindre la recherche dans l’espace en demandant à DevonThink de ne rechercher que dans le dossier spécifié et dans ses sous-dossiers.
Dans les outils de recherche se cache le troisième point fort de DevonThink, qui repose comme les deux autres sur l’analyse textuelles des documents (v. ci-dessous Fig. n°4). Il s’agit ici d’analyser le contexte dans lequel est employé un mot et de proposer des autres mots qui semblent appartenir au même thème général. Dans chaque document DevonThink extrait les mots qu’il estime les plus importants, il érige ensuite ces mots au rang de mots-clé pour comparer dans un troisième temps les mots-clé des différents documents de la base de données. Il est bien sûr possible d’afficher les mots-clé de chaque document, mais c’est le processus inverse qui est réellement utile: trouver les documents à partir d’un mot-clé. C’est pour cette raison que l’analyse du contexte dans lequel sont employés les mots-clé dans les documents de la base de données est si importante. Cherchez le contexte du mot «contrat», et DevonThink vous suggèrera les mots-clé «consentement», «clause», «stipulation» «conclu», «obligation», «volonté», «cocontractant», «nullité», «objet», «vente», «exécution», etc.
 |
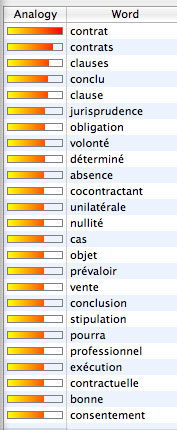 |
| Fig. 3: Correction orthographique basée sur le mot "contrat". Le logiciel propose semblables à "contrat" qui lui semblent pertinents. | Fig. 4: Recherche contextuelle basée sur le mot "contrat". Le logiciel recherche le contexte dans lequel est employé le mot "contrat" et renvoie une série de mots-clé employés dans le même contexte. |
DevonThink est le catalogueur-gestionnaire de fichiers le plus évolué du marché. Son intelligence artificielle le place au dessus de tous ses concurrents. En réalité, c’est bien plus que cela : il n’a aucun concurrent véritable en matière d’analyse textuelle et contextuelle des documents. Le choix est donc simple : si vous avez peu de documents, des documents à archiver que vous ne consulterez probablement plus, ou des documents suffisamment simples pour être identifiés par le titre du fichier (des morceaux de musique ou des films, par exemple), DevonThink n’est pas nécessaire. En revanche, si vous avez beaucoup de documents, que ces documents sont relativement complexes et que le titre du fichier ne reflète pas le contenu avec suffisamment de précision (pour des notes de recherche, par exemple), que vous avez besoin de les consulter ou de les modifier assez souvent, et qu’il existe plusieurs classements possibles, exclusifs les uns des autres, alors DevonThink est ce qu’il vous faut.
Le 20 novembre 2006,
mis à jour le 26 avril 2009,
mis à jour le 17 février 2010.