Usenet, alternative au P2P
⏤Vous connaissez tous le P2P, qui signifie «Peer-to-peer» ou «de pair à pair» en français. Grâce au P2P vous pouvez vous connecter à un réseau sur lequel vous rejoignez des millions d’internautes. Les fichiers de toutes les personnes au réseau étant mis en partage, ils ne vous reste plus qu’à lancer votre recherche et à choisir ce que vous voulez télécharger. Vous piochez chez eux, ils piochent chez vous. C’est le prinipe du vénérable Napster qui fut à l’origine de la création - du P2P… - et de bon nombre de ses successeurs (tels que Kazaa, LimeWire, eDonkey/eMule, etc.).
Comme vous n’êtes pas sans le savoir, le P2P dérange les majors, maisons de disque et producteurs de cinéma. Cela génère en effet un important manque à gagner pour eux: tout ce qui est téléchargé gratuitement n’est pas acheté. C’est comme ça que se distribuent les MP3 et autres DivX. Les majors ont donc fait tout ce qui était en leur pouvoir pour détruire le P2P (voir les nombreux article à ce sujet dans la section Internet de ce blog).
Dans certains cas, leurs actions ont été efficaces. C’est le cas des architectures Napster: un serveur centralise les connexions entre les différents pairs, il suffit de fermer le serveur pour faire tomber tout le réseau. Dans d’autres cas, les majors n’ont aucun moyen de nuire au réseau: c’est le cas des réseaux dits «décentralisés» qui ne reposent pas sur un serveur central (en fait, chaque pair fait office de mini-serveur).
Mais si les réseaux centralisés et décentralisés sont très différents de par leurs modes de fonctionnement, ils ont en commun que leur utilisation est, au regard de la loi française, illégale. C’est sur ce point, très important, qu’il ne faut pas faire de confusion. La législation française permet de télécharger (ce qui a été confirmé par un arrêt de la Cour d'appel de Montpellier du 10 mars 2005, en attendant confirmation ou infirmation de la Cour de Cassation), mais pas d'uploader. [Mise-à-jour : l’arrêt de la Cour de Montpellier a été cassé par la Cour régulatrice qui a jugé que la contrefaçon est constituée tant par l’upload que par le download.] Comme je l’ai expliqué ci-dessus, le principe même est que tout le monde pioche chez tout le monde. Vous téléchargez quand le fichier vient de chez quelqu’un d’autre et va vers chez vous, et vous uploadez lorsque le fichier part de chez vous et va vers quelqu’un d’autre.
Le téléchargement est donc parfaitement légal. Ce qui ne l'est pas est le partage des fichiers. [Les deux procédés sont sont placés à la même enseigne] Or, pour que les réseaux de P2P fonctionnent, il faut que tout le monde partage (sinon plus de sources, plus de téléchargements). La plupart des clients (logiciels utilisés pour accéder aux réseaux) ne permettent même pas de désactiver l’envoi.
Au vu des dernières évolutions de la jurisprudence et de la loi, il est nécessaire d’indiquer à ce stade que le téléchargement d’oeuvres contrefaisantes sur Usenet est un délit, de la même manière que le téléchargement illicite sur les réseaux P2P. La même solution s’applique également au téléchargement direct HTTP (MegaUpload, Rapidshare, etc.) et au streaming, même si la dernière loi répressive (HADOPI) ne vise que les réseaux P2P. Le reste de l’article demeure toutefois valable : il existe des contenus libres de droits sur Usenet, qui peuvent être téléchargés sans commettre de délit de contrefaçon.
Une alternative au P2P: Usenet
Il s’agit donc d’un cercle vicieux: pour que le P2P existe, il doit être illégal. C’est pourquoi il est préférable de se tourner vers une autre solution de téléchargement (qui n’est plus du P2P) parfaitement légale: les newsgroups. Les newsgroups présentent 2 avantages majeurs: 1) leur utilisation est légale, 2) la vitesse de téléchargement est constante et égale au maximum de votre bande passante. Pour le dire d’une autre manière: avec eMule vous mettrez 48 heures pour télécharger illégalement un film, alors qu’avec Usenet vous mettrez 2 heures pour télécharger ce même film en toute légalité.
Le seul point noir est que l’accès à Usenet n’est, pour la plupart d’entre nous, pas gratuit. Les heureux abonnés à Free auront accès aux groupes binaires (ceux qui contiennent les fichiers à télécharger), alors que les abonnées de tous les autres fournisseurs d’accès internet français devront souscrire un abonnement auprès d’une société tierce offrant un accès aux newsgroups. Je vous recommande à ce sujet Newshosting, téléchargements illimités pour 15 euro / mois, approximativement.
Le principe d’Usenet est le suivant: une personne envoie un fichier à son serveur d’accès Usenet. Le serveur transfère ce fichier à tous les autres serveurs dans le monde. Il devient possible de télécharger le fichier directement depuis le serveur. Cela explique les vitesses de télélchargement halucinantes. Là où le P2P fait d’utilisateur à utilisateur (les founisseurs d’accès limitent bien evidemment le vitesse d’upload au maximum), Usenet met en relation le client directement avec son serveur.
Il est important d’expliquer à ce propos le principe de rétention. Puisque les fichiers sont stockés sur les serveurs et que l’espace disque de ces serveurs n’est pas illimité, tous les fichiers vieux de plus de X jours sont effacés. Le X représente le taux de rétention. Plus le taux de rétention est élevé plus vous aurez accès à des vieux fichiers. Le taux de rétention moyen se situe entre 1 et 2 semaines. Ne choisissez pas un founisseur d’accès aux newsgroups qui offre un taux de rétention inférieur à une semaine.
Utilisation des newsgroups
Après avoir pris un abonnement, vous devez trouver un logiciel pour accéder aux newsgroups. Pour PC, je vous conseille GrabIt ou NewsBin Pro, et pour Mac Unison (celui que l’utilise) ou Hogwasher. la configuration de ces outils est relativement simple, je n’en parlerai donc pas ici. Cependant, si vous avez des problèmes, vous pourrez obtenir des informations dans cet article sur Ratiatum.
Une fois votre client installé et configuré, choisissez un groupe et ouvrez le. Vous pouvez par exemple commencer par alt.binaries.divx.french ou alt.binaries.movies.divx.france.
Les fichers seront automatiquement regroupés par votre logiciel qui les présentera de cette manière:
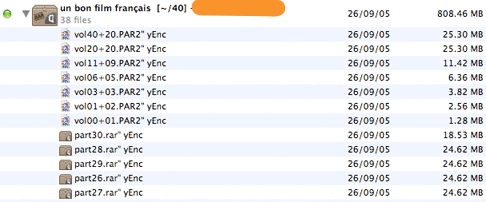
Double cliquez sur l’archive, et le téléchargement commencera. Vous verrez, le débit est énorme ! Dans l’exemple ci-dessous, j’ai 4 connexions actives. En effet, les fournisseurs d’accès aux newsgroups limitent le nombre de connexions actives simultanément. Pour Newshosting, pas plus de 4 à la fois (ce qui est très largement suffisant).
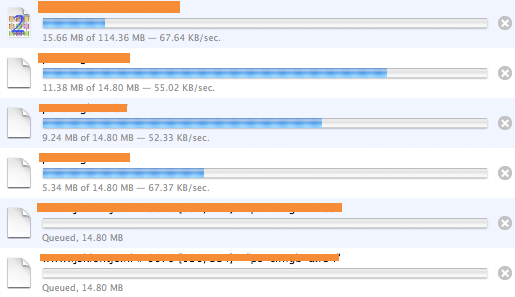
Vous avez sans doute remarqué que les fichiers ne portent pas l’extension AVI (pour les DivX) ou MP3. C’est en effet un problème avec Usenet: les fichiers sont découpés en plusieurs fichiers plus petits et compressés. Vous téléchargez tous ces petits fichiers, et un logiciel les assemble pour vous, de manière à obtenir le gros fichier original (split ‘n merge). Mais des parties de ces petits fichiers peuvent se perdre en route, ne jamais arriver jusqu’à vous… et c’est bien bête d’obtenir un fichier de 3 GO corrompu -et donc inutilisable- parce qu’il lui manque 1 MO de données ! Des outils ont donc été créés pour remédier à ce problème.
Pour résumer, une fois les fichiers téléchargés:
-
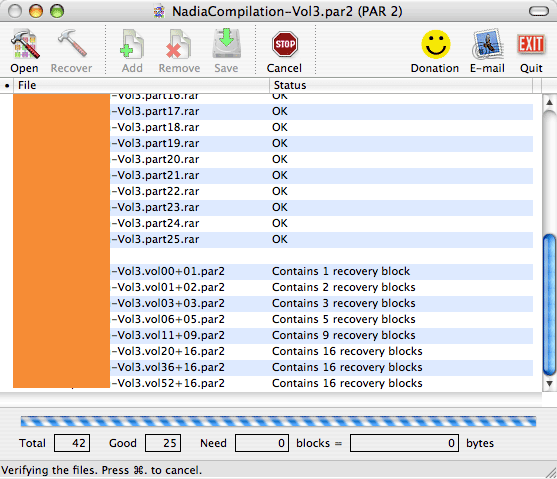
Vérification de leur intégrité, et réparation le cas échéant. Utilisez pour cela QuickPar pour PC, et MacPar pour Mac.
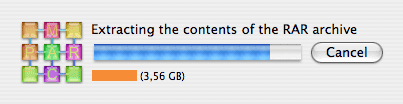
Décompression des archives et extraction des données. Utilisez pour cela WinRar pour PC, le logiciel MacPar pour Mac intégrant déjà un moteur de décompression RAR.
</p>
MacPar en action: vérification de l'intégrité des fichiers
MacPar en action: reconstruction du fichier original à partir des archives
Widgets payants
⏤La dernière version du système d’exploitation Apple, Mac OS 10.4 «Tiger», intègre un logiciel assez intéressant: Dashboard. Une pression sur la touche F12 du clavier, et un écran rempli de gadgets (appelés «widgets») se superpose au bureau.
Ces petits machins c’est très utile ! Non… en fait c’est totalement superflu. En plus ça bouffe plein de mémoire et de ressources processeur. Bref, il ne vaudrait mieux ne pas les utiliser. Mais là n’est pas la question.
Les widgets sont très faciles et très rapides à créer. C’est pour ça qu’il y en a tant de disponibles sur internet. Des milliers, à peine quelques mois après la sortie de Tiger. Mais voilà, certains sont payants. Alors s’il faut payer quelques dollars pour un widget très utile, pourquoi pas. Mais certains widgets sont une pure et simple arnaque. Alors ne vous faites pas arnaquer: virez les ou hackez les (enfin, faites ce que vous voulez ;) ).
D’ailleurs, si tous les widgets ne sont pas gratuits, ils sont tous open-source ! Et oui… ils reposent sur une structure XHTML/JavaScript. Ils ne sont donc pas compilés, et il devient très facile de faire sauter toutes les protections d’un widget ! La protection la plus classique affiche un écran noir devant le widget à chaque ouverture de Dashboard (à chaque pression sur F12), avec un bouton sur lequel cliquer pour accéder au widget. Acheter le widget permet d’enlever cet écran noir de manière définitive. Payez ou lisez ce qui suit, faites votre choix.
Il faut d’abord ouvrir le «paquet» que constitue le widget. Pour cela, il faut se rendre dans le répertoire des widgets (Macintosh HD/Utilisateurs/votre_nom/Bibliothèque/Widgets/), cliquer-droit sur l’icône du widget, et choix de l’option Afficher le contenu du paquet.
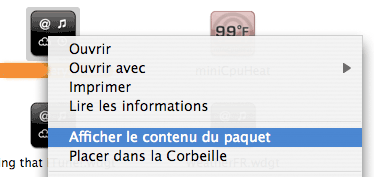
Trouvez ensuite le fichier nom_du_widget.js. Ouvrez ce fichier dans un éditeur de texte (BBEdit, SubEthaEdit, etc.).
La structure du fichier est la suivante:
Interprétation de statistiques Web
⏤Cet article a pour but d’expliquer dans les grandes lignes ce qu’il faut retenir d’une analyse statistique des visites d’un site web. Je me suis basé sur le logiciel AwStats pour écrire cet article, mais les principes sont les mêmes pour tous les autres logiciels du même type. Je vais donc procéder en commentant les résultats de chacune des grandes catégories de statistiques, sans rentrer dans les détails ni fournir d’explications techniques trop poussées.
Résumés et notions de base
-
Trafic 'vu'
Trafic 'non vu'
Le traffic ‘vu’ correspond aux visiteurs normaux, c’est-à-dire les personnes physiques derrière leurs ordinateurs. Le traffic ‘non vu’ correspond aux «bots» (ou «spiders») des moteurs de recherche. Les moteurs de recherche (Google, Yahoo, MSN, Lycos, etc.) utilisent des logiciels intelligent qui parcourent le Web à la recherche de nouvelles pages à indexer. Ces logiciels s’appellent des «bots» (pour «robots»). Ils ne «visitent» pas les sites, ils se contentent de charger les pages présentes et d’analyser leur code source à la recherche de mots-clé caractérisant le site à indexer. Ils génèrent du traffic (en bande passante), mais ce ne sont pas des visiteurs humains.
-
Visiteurs différents
Visites
Pages
Hits
Bande passante
Un visiteur est identifié par son adresse IP (identifiant attribué à chaque ordinateur présent sur Internet par les fournisseurs d’accès). Chaque nouvelle adresse IP est donc considérée comme un nouveau visiteur par le logiciel de statistiques. L’adresse IP peut être dynamique, semi-dynamique ou statique. Ont une adresse dynamique les utilisateurs de modems: l’adresse IP change à chaque connexion. Ont une adresse semi-dynamique les utilisateurs de l’ADSL: l’adresse IP change à intervalle fixe (chez Wanadoo, toutes les 24 heures) bien qu’il soit possible qu’une même adresse soit réaffectée plusieurs fois de suite au même utilisateur. Ont une adresse fixe certains particuliers ayant l’ADSL (pas en France, mais en Espagne avec Telefonica par exemple), et la plupart des grosses entreprises (avec accès internet dédié), les universités et beaucoup d’autres institutions publiques.
Les visites sont calculées pour chaque visiteur: combien de fois est-il venu sur le site. Le même principe d’adresse IP que celui expliqué ci-dessus est utilisé. Cependant, si un visiteur quitte le site et revient dessus par la suite, deux visites seront comptabilisées. Le nombre de visites est donc fiable, tandis que le nombre de visites par visiteurs ne l’est pas tellement.
Le nombre de pages chargées correspond au nombre de fichiers affichés à l’écran. Le nombre de ‘hits’ correspond au nombre de fois où un client est entré en relation avec le serveur. Par exemple, le téléchargement d’un fichier le compte pas pour une page vue, mais incrémente le nombre de hits.
La bande passante est le nerf de la guerre sur Internet. Les sites internet sont construits avec des fichiers: du code source, des images, vidéos, musiques, etc. Lorsqu’un utilisateur visionne une page, il demande au serveur de lui envoyer ces fichiers. Chaque octet de ces fichiers est pris en compte dans le calcul du traffic utilisé. Par exemple, si un fichier fait 1 MO et que 1000 visiteurs le chargent, la bande passante utilisée sera de 1*1000 MO = 1 GO. La bande passante étant très chère (beaucoup plus chère que l’espace), il est conseillé d’alléger ses pages de manière à en consommer le moins possible.
Historique temporel
Tous les systèmes d’analyse présentent une série d’information:
-
Historique mensuel
Jours du mois
Jours de la semaine
Heures
Il s’agit ici de déterminer les valeurs correspondant aux notions expliquées ci-dessus pour
-
Les mois complets. C'est la somme des valeurs de tous les jours du mois. Le total mensuel des visiteurs, visites, pages, hits et de la bande passante. On peut ainsi voir très rapidement l'évolution à long terme de la fréquentation d'un site: a-t-elle progressé ou regressé pendant les 6 derniers mois ?
Chaque jour du mois. Il s'agit du même principe que pour les mois complets, mais en jours et sur le mois courant. Ce mois-ci, quel est le jour qui a vu le plus de traffic sur le site ?
Jour de la semaine. Il s'agit du bilan des 7 jours de la semaine, sur 1 mois. C'est à dire que les statistiques des 4 lundi du mois sont additionnées, pour constituer les valeurs du "lundi". On peut ainsi voir pendant quel jour de la semaine il y a en général le plus de visites.
Heures. Il s'agit du même principe que pour le jour de la semaine, mais reporté aux heures. On peut ainsi voir, sur un mois, quelles ont été les heures les plus creuses (habitellement vers 5H du matin en France), de manière à planifier une maintenance en dérangeant le moins de visiteurs possible.
</p>
Domaines et hôtes
Les domaines présentent en général la procevance physique des visiteurs, c’est-à-dire le pays depuis lequel ils naviguent. L’identification se fait grâce aux informations de nom de domaine, ce qui explique la présence de références comme «Commercial» (.com) ou Network (.net).
Les hôtes sont les références des porteuses Internet des fournisseurs d’accès. Par exemple, si je vois amontsouris-152-1-70-175.w83-202.abo.wanadoo.fr, je peux apprendre deux informations très rapidement: le fournisseur d’accès est Wanadoo et le DSLAM (passerelle ADSL) est celle de la région parisienne (montsouris). Il y a donc une majorité de visiteurs parisiens ayant wanadoo.
Mais ces statistiques ne sont pas totalement exhaustives, ni totalement infaillibles. En effet, certains hôtes sont masqués (ceux derrière un Proxy par exemple). Dans ce cas, un message du type «IP non résolue» apparaîtra.
Spiders/Robots
Voir plus haut, concernant le traffic ‘non vu’ généré par les moteurs de recherche.
Durée des visites
Simplement, la durée moyenne d’une visite.
Types de fichiers
Il s’agit des fichiers les plus demandés au serveur. Je ne vais pas faire ici un cours de construction de site Web, mais il faut quand même connaître les grands types de fichiers:
-
HTML (statique) : ces fichiers sont le coeur du site, ils stockent le contenu et définissent les propriétés du contenant. Ils sont présents à la récine du site et sont envoyés tels quels au client.
PHP+SQL (dynamique): les fichiers PHP sont présents sur le serveur, mais contrairement aux fichiers HTML ils ne sont pas envoyés directement au client. Ils sont préalablement exécutés par le serveur, et c'est le résultat de cette exécution qui est envoyé au client. Ce produit n'est pas forcément de la même taille que le fichier source (ce qui est important en terme de bande passante).
CSS: fichiers définissant tous les aspects graphiques du site.
JPEG, PNG, GIF, BMP, etc: ces sont des images
SWF: contenu multimédia Macromedia Flash.
Pages et URL
Il s’agit de la liste des pages les plus visitées.
OS et Navigateurs
Il s’agit de la liste des systèmes d’exploitation et des navigateurs utilisés par les visiteurs. Les versions sont également indiquées. C’est là qu’on se rend compte qu’il y a encore plein de crétins qui utilisent InternetExploder.
Referers
(connexion au site par…)
Ces données indiquent les sources des connexions. C’est-à-dire l’endroit où était le visiteur immédiatement avant d’arriver sur le site faisant l’objet des statistiques. Par exemple, si vous cliquez sur un lien depuis une page de résultats de recherche Google, le site visité enregistrera Google comme référant.
Mots et phrases clé
Ce sont les mots et les phrases les plus vues sur le site.
Divers
Il s’agit d’une série d’informations concernant les plug-ins aux navigateurs utilisés lors de la visite sur le site. Si vous n’avez pas d’Applet Java sur votre site, vous verrez pas exemple un taux d’utilisation de Java de 0%.
Statuts HTTP
Ce sont des codes standardisés renvoyés par le serveur en réponse à une requête non valide du navigateur. Chaque code correspond à un type d’erreur déterminé. Par exemple, l’erreur numéro 404 signifie que le visiteur a tenté d’accéder à un document qui n’existait pas (par exemple en faisant une faute de frappe dans l’adresse). Le code 403 signifie qu’un visiteur non autorisé a tenté sans succès d’accéder à une zone protégée par un mot de passe (.htaccess), et ainsi de suite.
• 1374 mots • #Internet #Web #serveur #statistiquesUn problème d'encodage, peut-être ?
⏤ Quelques informations utiles sur l'encodage, les charsets et les malencontreux hiéroglyphes qui apparaissent parfois dans nos textes ! • 534 mots • #apple #Internet #programmation #Linux #Web #Windows #langue #bases de données #plaintextAmphi blindé
⏤Un petit coup de gueule en passant, ça fait du bien. Au programme, aujourd’hui, l’amphi de mon dernier cours de la matinée qui était blindé de chez blindé. Plein à craquer. Plusieurs centaines de places, toutes occupées. Les escaliers à 4 personnes par marche. Les allées entre les rangées pleines de gens assis par terre. C’est inadmissible ! Comme je n’ai pas envie de m’exploser le dos, je suis parti.
Comme cet article est un coup de gueule, je n’ai pas de grande analyse à faire. Ce sera donc rapide.
Je trouve totalement inadmissible qu’un amphi soit plein. Il n’est pas normal que dans un pays comme la France des étudiants doivent subir des cours de 1h30min assis par terre. Ca m’est arrivé 3 fois l’année dernière, d’avoir à subir des cours à ras le sol. Mais cette fois-ci, c’est différent: même par terre, il n’y avait plus de place. Je ne suis pas entré dans l’amphi, je suis rentré chez moi.
Et le prof qui trouve le moyen de faire une réflexion désobligeante et pleine de mépris aux gens assis par terre, ou debout au fond contre le mur. Ca ne mérite pas d’être prof ça. C’est lamentable de ne pas comprendre que 1) si on arrive avec 5 minutes de retard à un cours à midi, c’est dans la majorité des cas parce qu’un cours précédent s’est terminé à l’heure pile à laquelle il devait se terminer, et qu’il nous a fallu 5 minutes pour faire le trajet d’un amphi à un autre (envidemment le second cours commence à l’heure même où le premier se termine, même pas 5 minutes de décalage); 2) ceux qui viennent en cours, et qui subissent le cours dans ces conditions, sont vraiment très motivés ; alors c’est stupide de les rabaisser.
Ce coup de gueule est avant tout destiné à l’administration de l’éducation nationale. On veut faire des stats. On veut admettre tout le monde sur les bancs de l’université. On veut faire du clientellisme en permettant aux étudiants de composer leur menu entre des dizaines d’options. Tout cela au prix de la qualité de l’enseignement. Ce qui était jusqu’à lors déplorable devient totalement inadmissible lorsque certains, légitimes, se trouvent exlus par la force des choses.
Refusez des inscriptions ou multipliez les cours ou construisez des amphis plus grands. Et surtout apprenez à compter, et sachez que 500 personnes ne tiennent pas dans un amphi de 400 places. Ne comptez pas sur le fait que bon nombre d’étudiants n’assistent pas aux cours d’amphi: 1 inscrit = 1 place, un point c’est tout.
• 430 mots • #sociétéA coup de spams...
⏤Le succès d’internet est avant tout le succès des e-mails. Pouvoir faire parvenir une lettre en quelques secondes, c’est merveilleux. Mais l’e-mail a sa contrepartie: le spam. Tout le monde a un jour été spammé comme tout le monde a un jour reçu de la pub dans sa boîte aux lettres.
J’ai choisi de rédiger cet article pour exposer mon point de vue quant au spam, expliquer comment ça marche, et surtout donner quelques conseils pour s’en protéger
Spam: définition

Le spam… c’est ça ! Des conserves américaines de viande. C’est une marque. Tout comme «Frigidaire», «Tuperware», «K-way» ou «fermeture Eclair» sont passés dans le langage courants. «Spam» désigne maintenant ce que les québécois se complaisent à appeler «pourriels». Des e-mails (bon, je le dis: courriels) pourris, en somme. De la pub sale. De la merde. On peut également dire qu’un spam est un e-mail non sollicité, mais ça ne serait pas vraiment exact. Ou du moins, ça ne l’est plus. Il y a encore 5 ans, j’aurais appelé «Spam» un message HTML bien écrit et bien présenté (avec des images et une belle mise en page) envoyé par une entreprise commerciale pour promouvoir ses produits. Je les considère maintenant comme des courriers normaux, au vu de ce qu’est le «vrai» spam. Le vrai spam, c’est un message de ce type (je vous en ai recopié un vrai de vrai !):
come and see Fat Witness cute innocent beauties turn into sleazy cum-loving whores in an eyewink! see them in action : http://es.geocities.com/walforduzxz/
Real fat Nice naughty nymphs welcome really big things in their tight rosebuds!
kqtGET OFF: http://es.geocities.com/walforduzxz/
»Dead men tell no tales. »The Best Wine Comes Out of an Old Vessel.
»Nah because dog ah play with yuh he nah bite yuh..
</span>
Voilà également l’en-tête partiel:
From: Melisa <melisa @start.no>
Subject: come and see Fat fresh floozies want more hot lollipops
To: [email protected]
</melisa>
Bon, alors autant le dire tout de suite, l’adresse de réception n’est pas la mienne. Je n’ai même jamais vu de «gflanagan» de ma vie. L’adresse d’envoi n’existe pas, il n’y a personne derrière. Le contenu du message est inexistant. Il fait référence a un site hébergé chez un hébergeur gratuit (tout pourri, en somme) plein de pub, et sans possibilité technique de développer un vrai service commercial.
Ce que j’en pense
Comme tout le monde, je pense que c’est petit, minable, pourri, moisi, dégueulasse, et quaetera. Et puis c’est stupide aussi, car n’allez pas me dire que quand vous recevez 300 spams dans la journée, il y a la moindre chance qu’un de ces spammeurs arrive à vous faire lire son message, aller sur son site, et sortir votre CB !
Mais beaucoup plus préoccupant, le fait que le spam ne revienne pas cher (beaucoup moins que la publicité imprimée sur papier) conjugé au fait qu’Internet ne connaisse pas de limite, entraîne des exagérations monumentales. On peut ainsi reçevoir plusieurs milliers de spams par jour si on laisse trainer son adresse e-mail un peu partout.
Je pense que le spam est le plus grand danger pour Internet. Si les gens reçoivent trop de spam, il n’utiliseront plus Internet. Ca sera la mort de l’e-mail, et ça sera terrible. Ou alors, nous seront tous contraints de signer nos e-mails numériquement. En tout cas, c’est un problème très important que les pouvoirs publics (de tous les pays du monde) devraient prendre plus au sérieux. En effet, le spam est relativement récent, alors il ne faut pas le laisser se développer !
Pourquoi tant de haine ?
Quand une de ces saletés de spammeurs obtient votre e-mail, il le stocke, le range, le classe. Il l’insère dans une liste, il grave la liste sur CD. Et puis il la vend, sa liste.
Un autre spammeur achète la liste (plusieurs centaines de milliers d’adresses), il loue un serveur SMTP dans un pays qui n’a pas de législation sévère (en Asie, ça fait fureur) pour une période d’une petite semaine. Il achète aussi quelques GO de bande passante. Bref, en tout une centaine d’euro. Et puis il envoie les spams: des millions de messages. Il propose dans ces messages d’acheter un produit X pour Y dollars. Il n’en a que 100 à vendre pour faire, mettons, 1000 euro de recette. Sur les millions d’e-mails envoyés, il y aura bien une centaine de pigeons. Il fera donc 900 euro de bénéfice très facilement et en très peu de temps.
Voilà pourquoi vous reçevez du spam. Encore à cause du nerf de la guerre…
Se protéger: ce qu’il ne faut pas faire
Comme je viens de l’expliquer, les maîtres-spammeurs constituent des listes d’adresses valides. Ils n’inventent pas les adresses e-mail, il les récupèrent à partir de diverses sources. Il faut donc apprendre à protéger son adresse par différents moyens.
-
Ne jamais laisser son adresse en clair sur une page web, ou dans le code source de cette page web. En effet, le web est parcouru en permanence par des robots qui collectent les adresses. Ils les reconnaissent au symbole @. Si vous devez laisser votre adresse, pensez donc à écrire: machin_arobase_truc.com, et tout le monde saura qu'il faut comprendre [email protected]. Les robots, eux, ne comprennent pas.
Encore des changements !
⏤Je ne tiens vraiment pas en place ! Au début, j’avais fait un site avec des templates Dreamweaver. Ca a tenu une quinzaine de jours avant que j’installe Dotclear pour blogger. Et puis j’ai laissé tomber Dotclear pour revenir au pur HTML. J’ai ensuite délaissé le site Valhalla parce que l’interface graphique ne me plaisait pas, et que je n’avais pas le temps d’en créer une autre. Cet été, j’ai pris le temps, et j’en ai créé une nouvelle. Dans le même mois -septembre 2005-, j’ai fait une autre version de l’interface Valhalla, totalement différente. La seule chose qui changeait, c’était les CSS. Côté HTML, j’avais retenu la leçon des templates Dreamweaver, et j’étais déterminé à créer un système qui ne m’oblige pas à changer de structure pour changer d’apparence. Et maintenant… le 4 octobre, je change encore !
Quand j’ai choisi de créer le site en PHP avec des includes XHTML+CSS, c’était pour les raisons suivantes:
-
Les bases de données ne sont pas toujours très stables. Il est facile d'altérer une table et de tout foutre en l'air. A l'inverse, une fichier HTML est du texte brut agrémenté de quelques balises. Ca ne peut pas planter: une fois que le fichier est sur le serveur, il ne peut plus bouger.
Le HTML simple (et j'ai bien veillé à ce que le code des fichiers contenant le texte soit réduit au maximum) ne changera pas de sitôt. Par contre, les bases de données et le moteur PHP sont en constante évolution. Sans parler du logiciel de blog...
Avec un fichier HTML, pas de problème d'encodage. Avec MySQL, c'est une autre histoire !
Je n'avais à l'époque aucune alternative à PHPMyAdmin pour exporter et dumper les tables MySQL. Or, à cause du timeout, il est impossible de faire ou de restaurer des fichiers de sauvegardes de plusieurs MO.
</p>
Heureusement, j’ai résolu certains de ces problèmes:
-
Je ne réalise plus mes sauvegardes avec PHPMyAdmin. Je peux exporter et dumper des fichiers de plusieurs centaines de MO sans aucun problème (si ce n'est que ça prend la journée...).
Fi des problèmes d'encodage: tout en ISO Latin 1 ! UTF-8, à la poubelle !
</p>
Quand aux motivations qui m’on poussé à adopter la structure blog (basé sur Dotclear), elles sont les suivantes:
-
Le moteur de recherche interne qui lance une recherche dans la base de données. Il est impossible d'implémenter un tel système de recherche si le contenu est stocké dans des fichiers HTML.
Le tri automatique par mois et années des articles. C'est mieux qu'à la main...
Le classement par catégories. Un double classement est trop lourd à gérer en HTML sans dupliquer les fichiers.
</p>
J’ai longtemps hésité entre WordPress et Dotcleat. Je préférais WP pour son interface. Mais j’ai finalement choisi Dotclear pour trois raisons:
-
Développé en France et totalement localisé en français, comme la plupart des thèmes.
Encodage ISO Latin 1 là où WP recommande l'UTF-8.
Les thèmes sont plus faciles à transformer de fixed-width à 100% width.
</p>
EDIT: J’ai encore changé… je suis passé à WP pour de bon. J’ai réussi à tout installer en ISO-8859-1, et j’ai trouvé le thème ultime (Aqua-Soft). Le seul souci que j’ai, c’est que je n’ai pas réussi à trouver -pour le moment- deux plugins que j’adorais dans Dotclear: le sommaire (celui de WP est moins bien car il ne classe pas les articles par mois), et le nombre de lectures par billet.
A propos de la largeur fixe dans les blogs, je ne comprend pas. Les blogs c’est fait pour écrire, non ? Alors pourquoi faire une zone centrale toute petite, puisque c’est la zone destinée à contenir le texte ? Je préfère vraiment avoir une zone très large (dans les 80% de la largeur de l’écran) pour que la lecture soit moins contraignante !
J’ai donc installé DotCleat. J’ai aussi installé le thème «Chaude Journée» et je l’ai adapté à mes besoins (vous l’aurez compris, en 100% width). Ensuite, j’ai inséré tous les articles dans la base de données, j’ai mis à jour les dates et je les ai classé par catégories.
I’m ready to blog ! :)
• 723 mots • #Valhalla